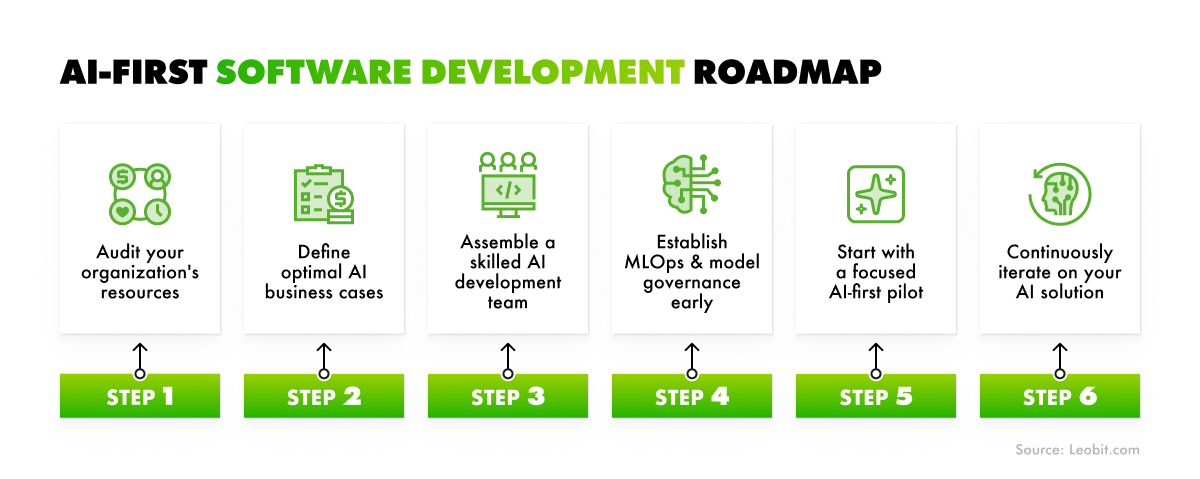
Whether you are building a system to support internal operations or a customer-facing product, the AI-first approach delivers solid advantages over systems where AI is added as an isolated feature after the fact. The difference is architectural: in an AI-first system, software engineering specialists design pipelines, data schemas, endpoints, and monitoring infrastructure around the requirements of the model from day one. Below, we outline the key benefits this produces in practice.
Cost structure that scales favorably
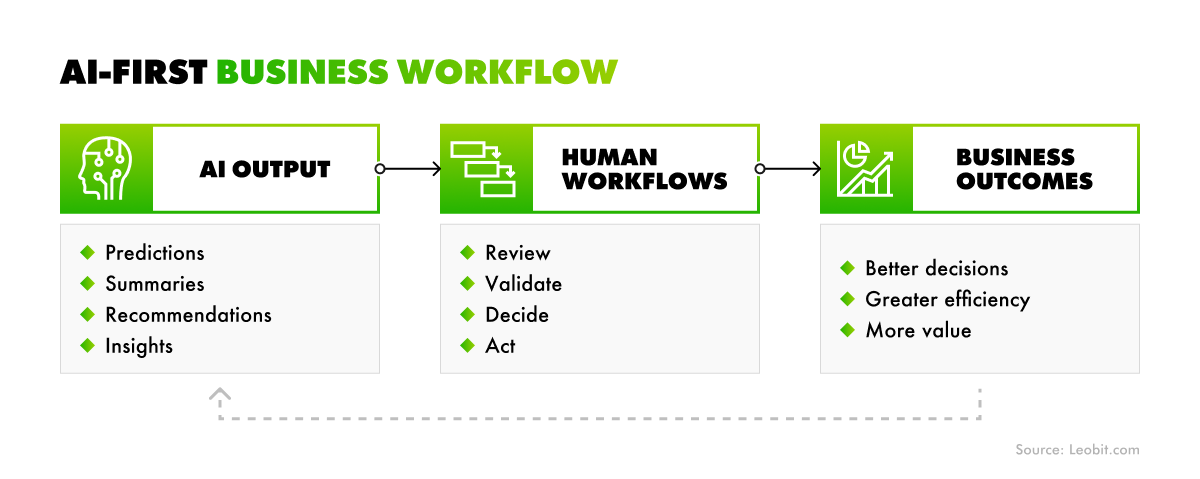
Systems built without AI implementation in mind tend to keep humans in the loop by default – not by design choice, but because the underlying business logic and data flows were never structured to hand off decisions to a model.
In AI-first products, things work differently. Software engineers design such solutions from the ground up around model outputs. The structure workflows so that decisions, validation, and routing can be handled autonomously, without a human bottleneck at each step. The result is a cost model that scales with compute, not headcount. This approach supports better control of AI costs as usage grows, aligning with the goal reported by 54% of company executives who are focused on achieving cost savings through artificial intelligence.
A product that improves with use
AI integration into the existing product doesn’t mean that the model won’t improve over time. However, in such products, improvement cycles tend to stay partially manual and engineering-dependent. Capturing and routing model outputs back into training pipelines requires deliberate effort that the original architecture wasn’t built to support.
On the contrary, AI-first systems make this structural from the start. AI models treat every user interaction as a training signal, with feedback loops for capturing, labeling, and routing outputs built into the architecture from day one. The result is a product that automatically compounds its capabilities over time. It can learn autonomously, getting smarter with usage rather than requiring continuous reengineering to absorb new AI capabilities.
Faster iteration on AI capabilities
In a retrofitted system, introducing new AI capabilities often means working around existing architecture. This typically involves:
- Adapting pipelines that weren’t built for powering AI models
- Using data schemas that predate the AI layer
- Testing changes without a proper evaluation infrastructure adapted to AI integration needs
In an AI-first setup, model updates, retraining, and testing are part of the default release cycle. The development team builds the system for constant iteration, so new AI features can be rolled out without major rework, and teams can react faster when business needs or market conditions change. That speed matters even more in today’s AI race, where 92% of companies are planning to increase their AI budgets this year to implement new features.
Reliability and observability by design
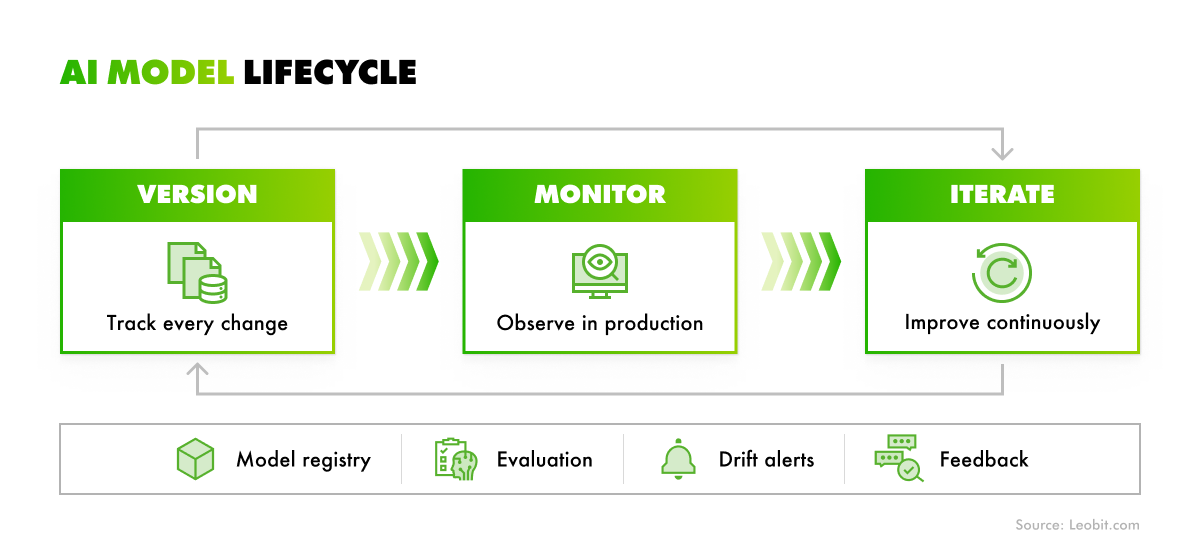
Adding AI to an existing product often means treating it as a feature rather than a core system. Without pre-built monitoring workflows, tracking model-specific signals like prediction drift, confidence score degradation, and input distribution shift can be more challenging. These problems tend to require deliberate instrumentation that the original architecture wasn’t designed to support.
An AI-first product treats model performance as production-critical from day one. It involves dedicated monitoring pipelines that track prediction drift, confidence score distributions, input feature statistics, latency percentiles, and cost per inference, alongside standard infrastructure metrics. If model quality drops, alerts and rollback mechanisms work the same way they would for a system outage. Model failure is treated as a product failure – with the same on-call ownership, incident response process, and postmortem expectations applied to any other critical system component.
Better observability matters because AI models don’t stay accurate forever. Across industries, performance can drift over time as real-world data changes. In areas like medical diagnostics, for example, studies have shown that models trained on historical data tend to become less reliable over time, especially when applied to new cases.
Improved user personalization
Feature-level personalization(e.g., a recommendation widget, a smart search bar) works within the data exposed at that specific touchpoint. To help an AI system understand the bigger picture, you often need to adjust how the model is configured or rethink the underlying data architecture.
AI-first systems approach this differently. User modeling and data architecture are built in from the start, giving the model continuous access to the full picture of behavior flowing through the system – across sessions, features, and interaction types. The result is personalization that adapts across the entire product experience, compounding in relevance over time as the model accumulates a richer signal about each user.
For customer-facing apps, such as e-commerce platforms, this can mean delivering more relevant product recommendations to users. For internal apps, like task management systems, it can take the form of an interface that automatically adapts to the needs of specific specialists.