Despite nearly every organization using some form of AI or machine learning, managing AI initiatives, particularly their financial aspects, is becoming increasingly difficult. According to the Flexera 2026 State of the Cloud report, 85% of organizations now consider managing cloud costs their top priority, while 68% rank cost optimization as their number one focus. Yet even with 63% already implementing FinOps practices, AI cost optimization remains a persistent challenge.

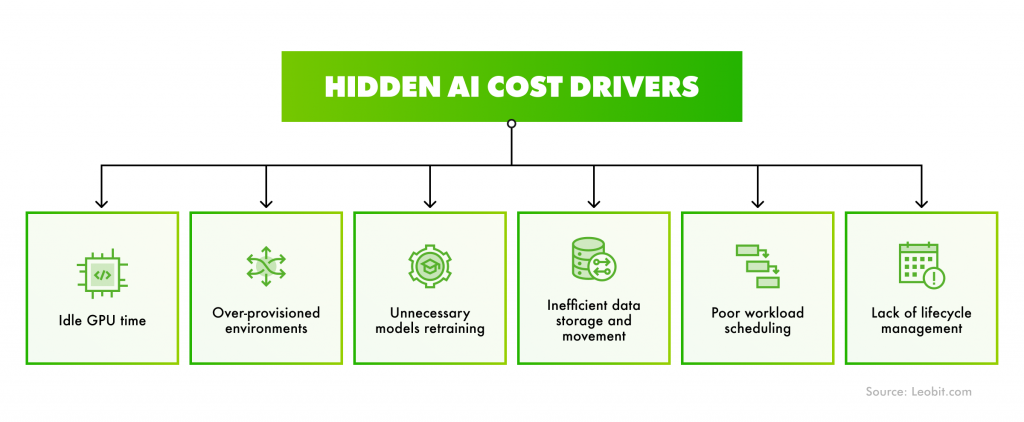
AI changes cloud economics by relying on costly, unpredictable GPU-driven workloads. Combined with rapidly evolving AI services, this creates cost complexity that most organizations are not fully prepared to manage.
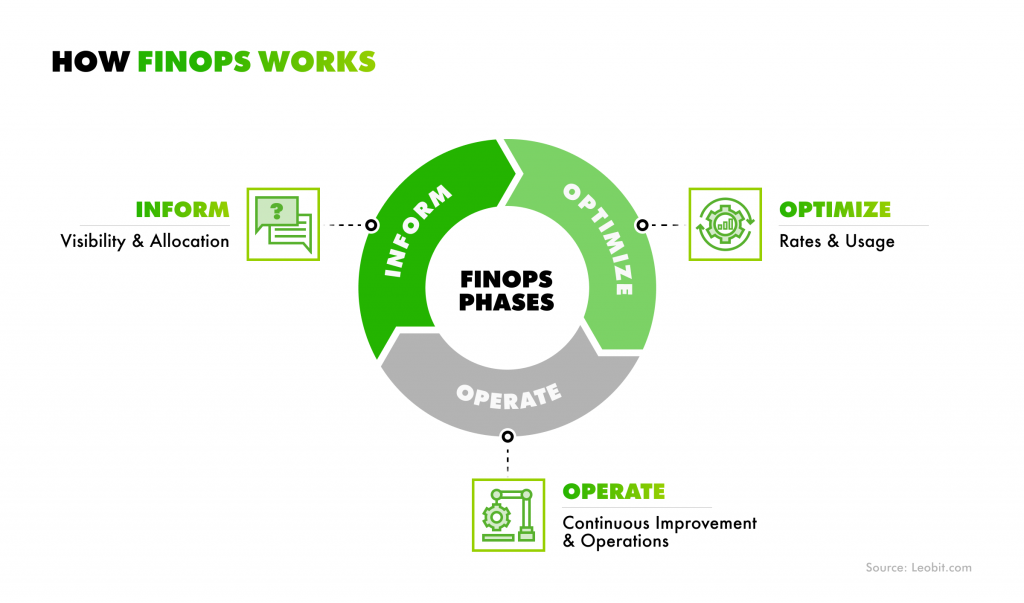
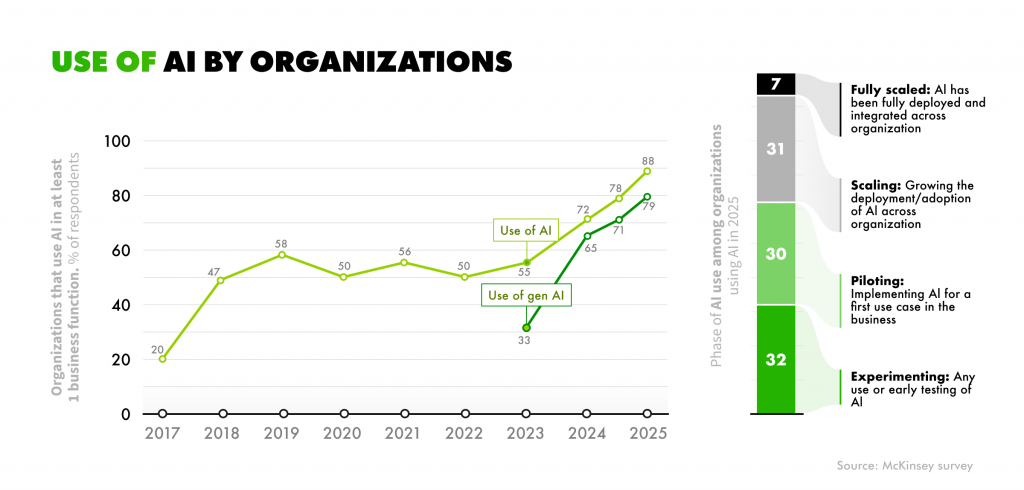
The scale of the issue is only growing. Gartner forecasts that worldwide IT spending will increase by 9.8% in 2026, surpassing $6 trillion, with AI as one of the primary drivers. Today, 88% of companies already use AI in at least one business function, 7% of which have already deployed and integrated AI across their business. That’s where FinOps becomes critical to avoid cost challenges connected with scaling AI initiatives. When applied right, FinOps provides visibility into AI spending and brings costs under control without slowing down innovation.
In this article, you’ll learn how to apply FinOps principles to AI development in a practical way without adding unnecessary complexity or slowing your teams down.