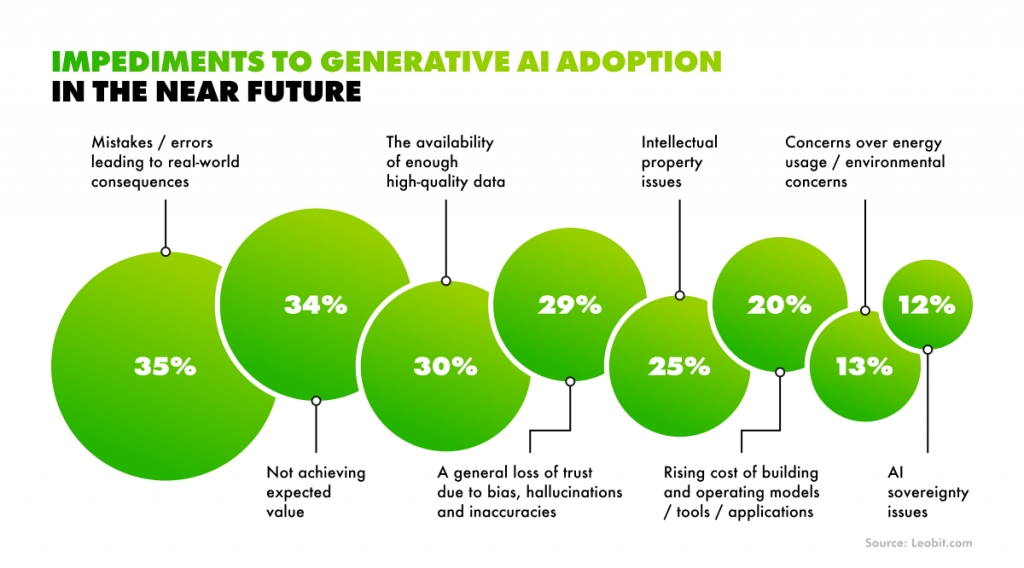
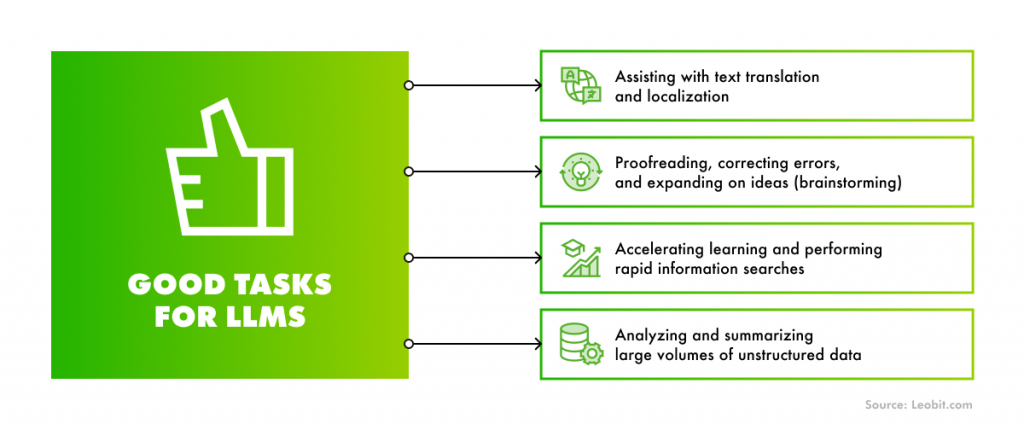
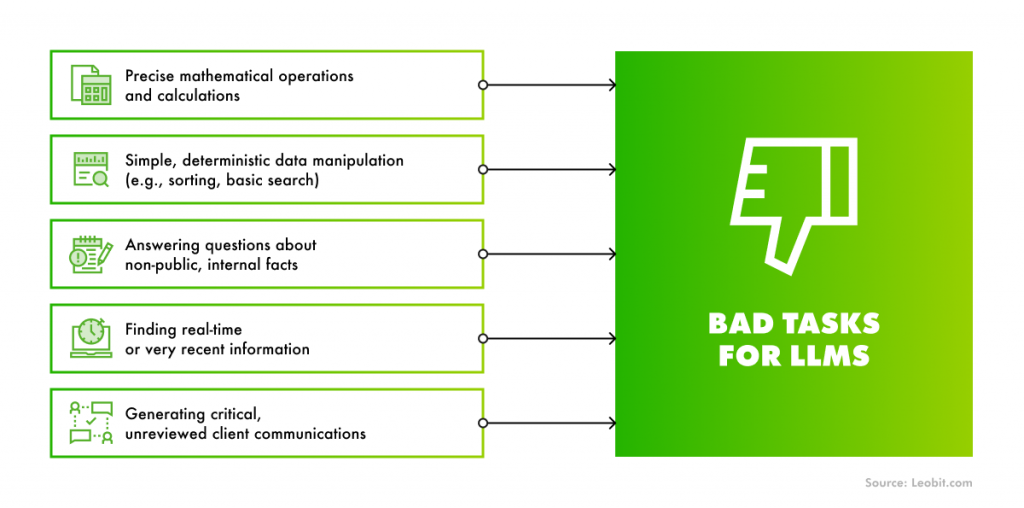
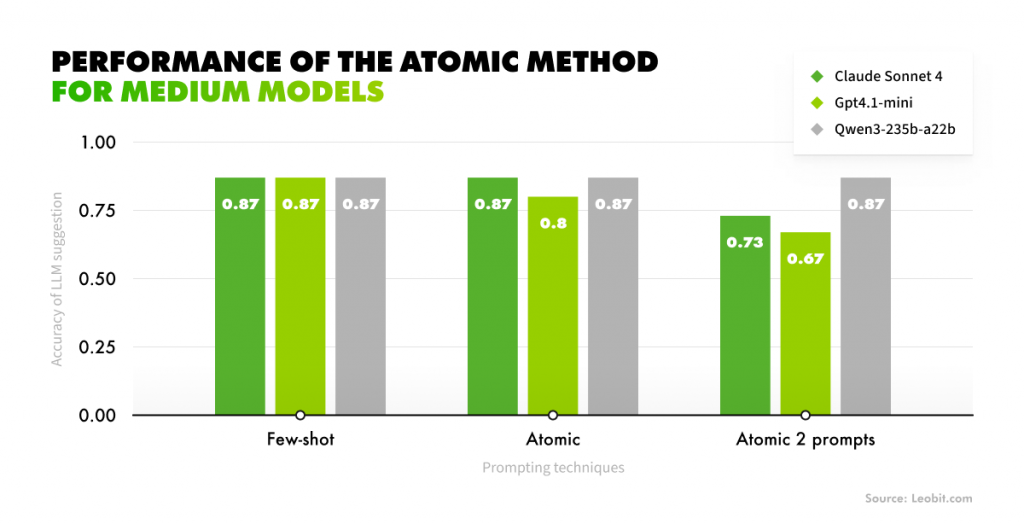
Today, businesses stand in the middle of a massive “LLM Gold Rush.” The excitement surrounding generative AI is driving a significant increase in investment. In fact, corporate AI investment has already reached $252.3 billion in 2024, with private investment climbing 44.5%. This has created a powerful “fear of missing out”, pressuring businesses to adopt AI immediately or risk falling behind.
But here’s the core problem: acting on this fear often leads to expensive, poorly planned projects that can eventually fail. Despite billions of dollars being invested, the reality is that success is not guaranteed. Data from industry professionals shows that a shockingly small number of machine learning projects, as low as 0-20%, are ever successfully deployed. That’s a lot of wasted time, money, and effort.
This article is designed to help you cut through the noise. We’ll expose the most common mistakes businesses make when rushing into AI and provide a clear framework to help you implement LLMs in a way that creates real, measurable value for your company.